

混同行列で使うF値って、数式を見る限り調和平均ですよね?
はい、その通りです。F値(特にF1スコア)は、精度(Precision)と再現率(Recall)の調和平均そのものです。
調和平均は、平均の中でも特に、複数の値のバランスを取るために使用される形式です。F1スコアは次のように定義されます:
この数式は、調和平均の一般的な形式に基づいています:
[ H = \frac{2ab}{a + b} ]
したがって、F1スコアはまさに精度と再現率の調和平均そのものです。
ここで、

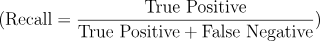
この調和平均は、精度と再現率のバランスを取るために使用され、どちらか一方が極端に低い場合にも敏感に反応します。そのため、F1スコアは不均衡なデータセットにおいても有用です。
F値はどのレンジに収まるのがいいの?
F1スコアは0から1の範囲を取ります。理想的には、F1スコアが1に近いほど良いとされています。具体的には以下の通りです:
- F1スコア = 1: 完全な精度と再現率を達成している場合。この場合、モデルの予測はすべて正しく、見逃しも誤認もないことを意味します。
- F1スコア = 0: 精度または再現率が0の場合。この場合、モデルの予測が全く役に立たないことを意味します。
一般的には、F1スコアが0.5以上であれば、モデルはある程度のパフォーマンスを発揮しているとみなされます。
ただし、実際の「良い」スコアの基準は、具体的なタスクやデータセットの特性によって異なります。
高いF1スコアが求められるシナリオもあれば、バランスが取れた精度と再現率が重要なシナリオもあります。
- 0.7 - 1.0: 非常に良いパフォーマンスを示しています。
- 0.5 - 0.7: まずまずのパフォーマンスですが、改善の余地があります。
- 0.3 - 0.5: パフォーマンスが低いとされ、モデルの改善が必要です。
- 0.0 - 0.3: 非常に低いパフォーマンスであり、モデルはほとんど役に立ちません。
したがって、F1スコアが高いほど、モデルが精度と再現率の両方で優れていることを示しています。
F値が0.7以上とかありえるのか?
そもそも精度(Precision)と再現率(Recall)はトレードオフの関係にあるでしょう?
F値が高い場合、いいモデルというよりも単なる過学習のおそれがある、ということではないのか?
ご指摘の通り、精度(Precision)と再現率(Recall)は一般にトレードオフの関係にあります。
つまり、一方を高めると他方が低くなる傾向があります。
そのため、F1スコアが高いということは、単に良いモデルを示すだけでなく、過学習のリスクも含んでいる可能性があります。
高いF1スコアの意味とリスク
- 高いF1スコア (0.7以上): これが現実的に可能な場合もあります。
特に、タスクが比較的簡単である場合や、モデルが非常に優れている場合です。
ただし、このような場合でも、過学習のリスクを注意深く監視する必要があります。 - 過学習のリスク: モデルが訓練データに対して過剰に適合し、未知のデータに対する一般化能力が低下する可能性があります。
この場合、F1スコアが高くても実際のパフォーマンスが低いことがあります。
過学習を避けるための対策
- 交差検証: 複数のデータセットに対してモデルを評価し、平均的な性能を確認する。
- 正則化: モデルの複雑さを制御するための手法を使用する。
- 適切なデータセット: トレーニング、検証、テストデータセットをバランスよく用意する。
- モデルの単純化: 不要な特徴量を削除し、モデルを単純化する。
- 学習曲線の確認: 学習曲線を確認して、トレーニングと検証のパフォーマンスの差を監視する。
実際のモデル評価
最終的には、F1スコアだけでなく、以下の点も含めて総合的に評価することが重要です。
- 他の評価指標: 精度、再現率、ROC曲線、AUCなど。
- ビジネス要件: モデルが解決するべき具体的な問題に対する適合性。
- データの特性: データの分布や不均衡の度合い。
過学習のリスクを減らしつつ、高いF1スコアを達成するためには、モデルの訓練と評価に対して慎重なアプローチが必要です。
繰り返しますが、0.7以上のF値を出す善良なモデルなど、存在するのか?
0.7以上のF1スコアを持つ善良なモデルは、特定の条件下で存在し得ます。
以下に、そのような状況や考慮すべき点を詳しく説明します。
0.7以上のF1スコアが達成可能な条件
- データセットの特性:
- クラスのバランス: クラスの不均衡が少ない場合、精度と再現率の両方を高く保つことが比較的容易です。
- 特徴量の質: 高品質で関連性の高い特徴量を持つデータセットでは、モデルのパフォーマンスが向上します。
- タスクの性質:
- タスクの難易度: 簡単なタスク(例えば、スパムメールのフィルタリングなど)では、高いF1スコアが達成されやすいです。
- ドメイン知識の利用: ドメイン知識を活用して特徴量を選択したり、モデルを調整したりすることで、パフォーマンスが向上します。
- モデルの選択と調整:
- 適切なアルゴリズム: タスクに適したアルゴリズムを選択し、ハイパーパラメータを適切に調整することで、パフォーマンスが最適化されます。
- アンサンブル学習: 複数のモデルを組み合わせることで、単一のモデルよりも高い性能を発揮することがあります。
実際の例
- スパムフィルタリング: メールのスパムフィルタリングでは、0.9以上のF1スコアが報告されることがあります。
これは、スパムと非スパムのメールが明確に区別できる特徴を持つためです。 - 画像認識: よく定義された画像分類タスク(例えば、手書き数字の認識など)では、0.95以上のF1スコアが達成されることがあります。
過学習のチェック
高いF1スコアが必ずしも過学習を意味するわけではありませんが、その可能性を排除するために以下の対策を講じることが重要です。
- テストデータでの評価: 未知のテストデータセットでモデルを評価し、訓練データと同様のパフォーマンスが得られることを確認します。
- クロスバリデーション: データを複数のサブセットに分けてモデルを評価し、一貫したパフォーマンスが得られることを確認します。
- 学習曲線の分析: 訓練データと検証データのパフォーマンスをプロットし、過学習の兆候がないかをチェックします。
結論
0.7以上のF1スコアを達成することは、適切な条件下では可能です。ただし、そのスコアが実際にモデルの一般化性能を反映しているかどうかを確認するために、過学習のリスクを評価し、モデルの性能を総合的に評価することが重要です。
では、一般的にはだいたいどのレンジに収まり、それでOKにすることが多いですか?
一般的に、F1スコアの評価基準はタスクの性質や業界の基準、データセットの特性によって異なります。しかし、以下の範囲が一般的な目安となります
一般的なF1スコアのレンジと評価
- 0.9 - 1.0:
- 非常に優れたパフォーマンス。高い精度と再現率の両方を達成していることを示します。
例えば、医療診断のように誤検出のコストが非常に高い分野では、これほど高いスコアが求められることがあります。 - 0.8 - 0.9:
- 優れたパフォーマンス。大多数の商用アプリケーションでこの範囲のスコアが達成されると、高品質なモデルと見なされます。
例として、製品の品質検査やカスタマーサービスのチャットボットなどがあります。 - 0.7 - 0.8:
- 良好なパフォーマンス。多くの実用的なアプリケーションでこの範囲のF1スコアは満足できると見なされます。
例えば、スパムフィルタリングや簡単なテキスト分類タスクなどです。 - 0.6 - 0.7:
- まずまずのパフォーマンス。改善の余地があるものの、実用上の価値は十分にあるモデルです。
例えば、初期段階のプロトタイプやパイロットプロジェクトで見られることがあります。 - 0.5 - 0.6:
- 最低限のパフォーマンス。パフォーマンスは低く、モデルの改善が強く求められます。
ただし、非常に難しいタスクやデータセットが不均衡な場合、この範囲のスコアでも一定の価値がある場合があります。 - 0.5未満:
- 不十分なパフォーマンス。モデルがタスクを適切に処理していないことを示します。
根本的な改善やモデルの再設計が必要です。
実際の評価基準の例
- テキスト分類:
- スパムフィルタリング:0.8 - 0.9
- ニュース記事分類:0.7 - 0.8
- 画像分類:
- 手書き数字認識(MNIST):0.9 - 1.0
- 一般物体認識(CIFAR-10):0.7 - 0.9
- 医療診断:
- 病気の検出:0.85 - 0.95(特に高い精度が求められる)
結論
F1スコアの評価基準は、タスクの具体的な要件や使用するデータセットによって異なります。
一般的には、0.7以上のスコアは多くの実用的なアプリケーションで「良好」と見なされますが、特定の分野やタスクではより高いスコアが求められることもあります。
スコアが0.6から0.7の範囲に収まる場合でも、実際のアプリケーションの文脈によっては十分に実用的であることもあります。

